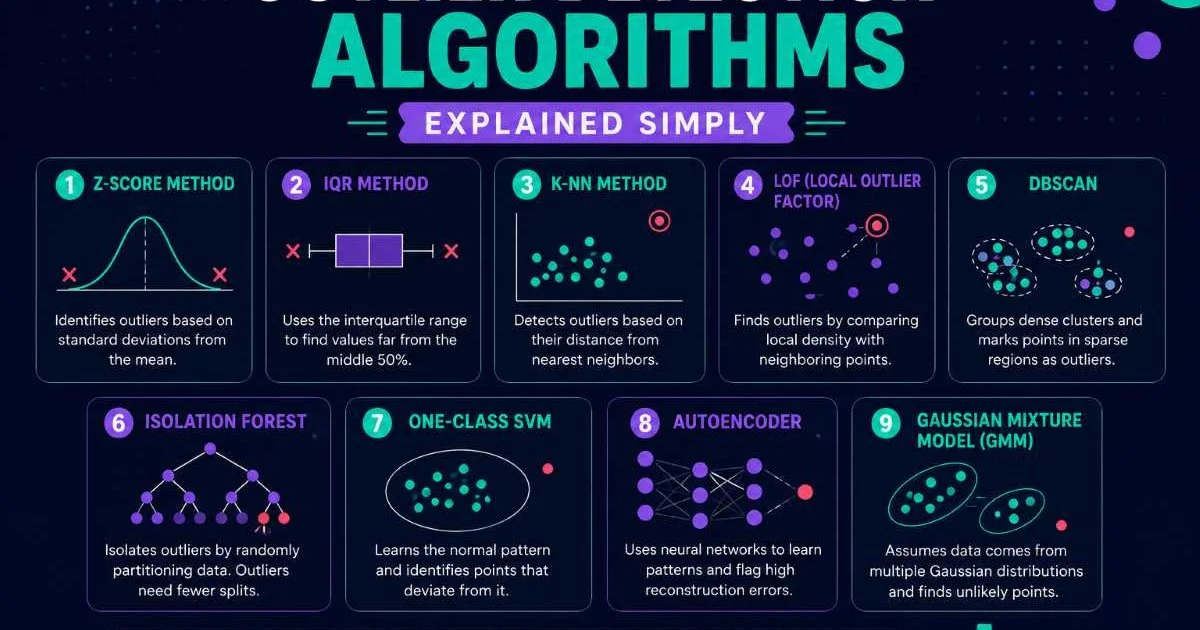
AI anomaly detection has become a frontline defense in cybersecurity, helping organizations spot threats that traditional rule-based systems routinely miss. As attack vectors grow more sophisticated, data analysts and scientists are turning to machine learning models that can identify unusual patterns in network traffic, user behavior, and system logs.
Fraud detection AI and outlier detection algorithms now process millions of events per second, flagging deviations that signal breaches, insider threats, or zero-day exploits. The stakes are high: a single undetected anomaly can lead to massive data exfiltration or financial loss.
This guide walks you through the practical steps of building and deploying an AI-powered anomaly detection pipeline for cybersecurity, from data preparation through production monitoring.
Key Takeaways
- Start with clean, labeled baseline data before training any anomaly detection model.
- Combine unsupervised and supervised methods for stronger threat coverage across attack types.
- Feature engineering on network logs dramatically improves detection accuracy and reduces false positives.
- Deploy models with real-time streaming pipelines to catch threats as they happen.
- Continuously retrain models because attacker behavior and normal baselines shift over time.
Step 1: Prepare Your Data Pipeline for Anomaly Detection AI
Identify Your Data Sources
Every effective cybersecurity anomaly detection system starts with the right data. You need network flow logs (NetFlow, IPFIX), authentication logs, DNS query records, endpoint telemetry, and application-level audit trails. Each source captures a different dimension of organizational behavior. If you're only analyzing firewall logs, you'll miss lateral movement inside the network or compromised credentials being used during normal business hours.
For a foundational understanding of how AI identifies unusual patterns in datasets, our guide to AI anomaly detection definitions and examples covers the core concepts. Once you understand the theory, you can map those principles directly to cybersecurity data sources. The key is breadth: attackers rarely leave footprints in just one log type, so your pipeline must ingest from multiple systems simultaneously.
Collect at least 30 days of baseline data before training your first model to capture weekly and monthly behavioral cycles.
Clean and Normalize
Raw security logs are messy. Timestamps arrive in different formats, IP addresses appear as both IPv4 and IPv6, and field names vary across vendors. Standardize everything into a common schema before feeding it into your models. Tools like Apache NiFi or Logstash can handle format normalization, deduplication, and enrichment (adding geolocation, ASN data, or threat intelligence tags to IP addresses).
Feature engineering is where domain expertise pays off. Instead of feeding raw packet counts into a model, calculate derived features like bytes-per-session ratios, login frequency per user per hour, or DNS query entropy scores. These engineered features give your data anomaly detection models much stronger signals to work with. A sudden spike in DNS entropy, for example, is a classic indicator of domain generation algorithm (DGA) malware communicating with command-and-control servers.
Step 2: Select and Train Your Detection Models
Unsupervised Approaches
In cybersecurity, most threats are rare and previously unseen, which makes unsupervised outlier detection especially valuable. Isolation Forest works well for high-dimensional network data because it isolates anomalies by randomly partitioning features, and rare points require fewer partitions. Autoencoders are another strong option: train them on normal traffic, then flag any input that produces high reconstruction error as potentially malicious.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) excels at identifying anomalous clusters in user behavior data. It naturally labels low-density points as noise, which often maps directly to suspicious activity. One practical advantage of DBSCAN is that you don't need to predefine the number of clusters. For network intrusion detection, this matters because the variety of normal behavior patterns shifts constantly with new applications, remote workers, and infrastructure changes.
Also Check: What Is Legacy Code Refactoring? A Complete Guide
Supervised and Hybrid Methods
When you have labeled attack data (from previous incidents, red team exercises, or public datasets like CICIDS2017 or UNSW-NB15), supervised models like Random Forest and gradient boosting (XGBoost, LightGBM) deliver superior precision. These models learn specific attack signatures and behavioral patterns that unsupervised methods might score as only mildly unusual. The tradeoff is that they won't catch truly novel attacks they haven't been trained on.
The strongest production systems use a hybrid approach. Run an unsupervised model for broad anomaly coverage and a supervised model for known threat patterns in parallel. Merge their scores with an ensemble layer that weights each model's confidence. This strategy gives you both the ability to catch zero-day threats and the precision to reliably identify known attack types without overwhelming your SOC team with false positives.
"The best cybersecurity detection systems never rely on a single model; they layer unsupervised breadth with supervised precision."
| Algorithm | Type | Best For | Handles Novel Attacks | Training Data Needed |
|---|---|---|---|---|
| Isolation Forest | Unsupervised | Network flow anomalies | Yes | Normal traffic only |
| Autoencoder | Unsupervised | High-dimensional log data | Yes | Normal traffic only |
| DBSCAN | Unsupervised | User behavior clustering | Yes | Normal traffic only |
| Random Forest | Supervised | Known attack classification | No | Labeled attacks + normal |
| XGBoost | Supervised | High-precision threat scoring | No | Labeled attacks + normal |
| Hybrid Ensemble | Both | Production deployment | Partial | Both types recommended |
Step 3: Deploy Real-Time Detection in Production
Build a Streaming Architecture
Batch processing is fine for historical analysis, but cybersecurity threats demand real-time response. Apache Kafka or Amazon Kinesis can ingest millions of events per second from your security infrastructure. From the message queue, route events through a stream processing framework like Apache Flink or Spark Structured Streaming, where your trained models score each event or session in near real-time. Latency targets should be under 500 milliseconds from event ingestion to alert generation.
Containerize your models with Docker and deploy them behind a lightweight API layer (FastAPI or Flask). This architecture lets you scale inference horizontally and swap models without downtime. Kubernetes orchestration with autoscaling policies handles traffic spikes during active incidents or network scanning events. Store model artifacts in a versioned registry (MLflow or similar) so you can roll back instantly if a new model produces unexpected results in production.
Never deploy a new model directly to production without running it in shadow mode alongside your existing system for at least one week.
Threshold Tuning and Alert Management
Setting the right anomaly score threshold is arguably the most impactful decision in your entire pipeline. Too sensitive, and your security operations center drowns in false positives. Too permissive, and real attacks slip through. Start by analyzing the score distribution on your validation set and picking a threshold that achieves at least 95% recall on known attack types while keeping the false positive rate below 1%. Adjust per data source, because network flow anomalies and authentication anomalies have very different base rates.
Integrate your alerts with existing SIEM platforms (Splunk, Elastic Security, or Microsoft Sentinel) through standard formats like CEF or STIX/TAXII. Following established cybersecurity best practices for incident response workflows means routing high-confidence alerts directly to tier-2 analysts while batching lower-confidence alerts for daily review. This tiered approach prevents alert fatigue, which is one of the primary reasons security teams miss genuine threats even when their detection tools flag them.
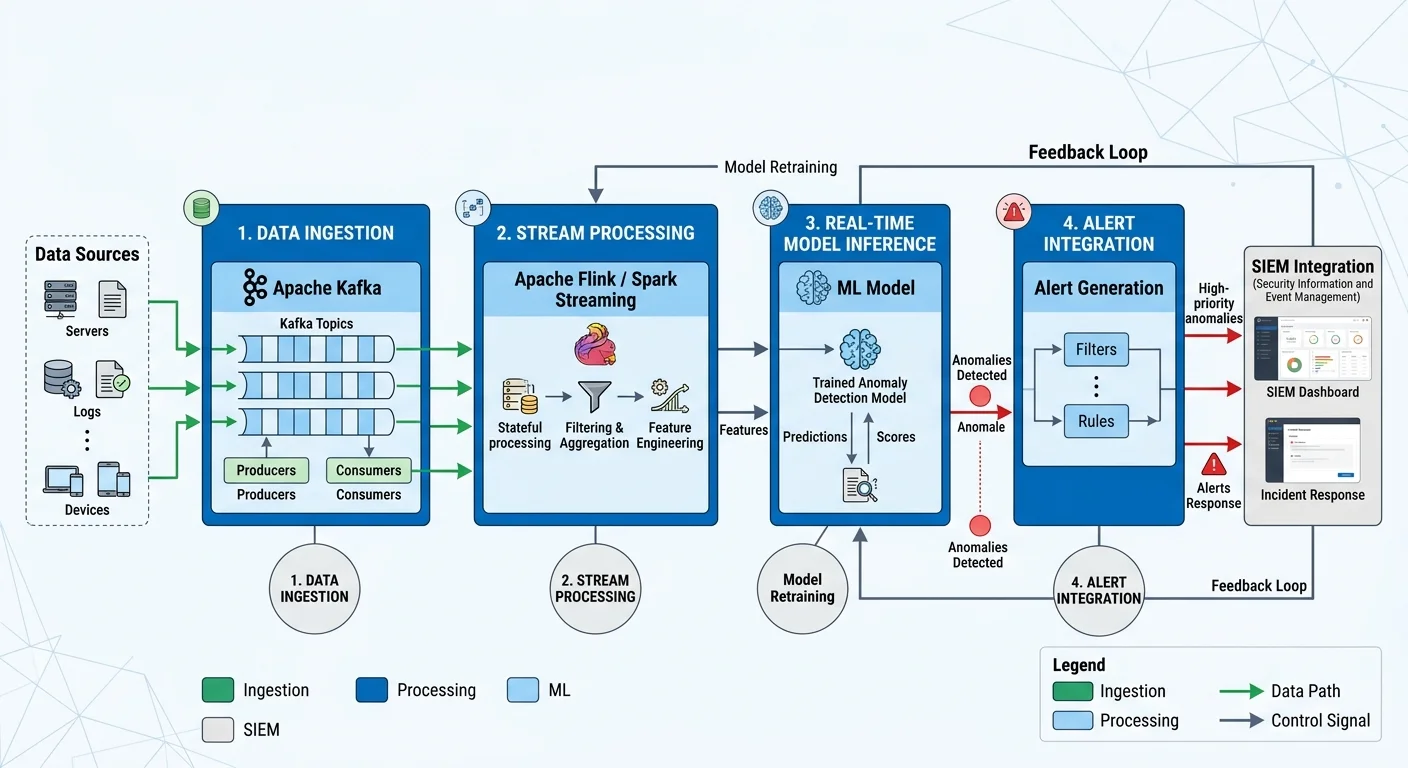
Step 4: Monitor, Retrain, and Improve Continuously
Track Model Drift
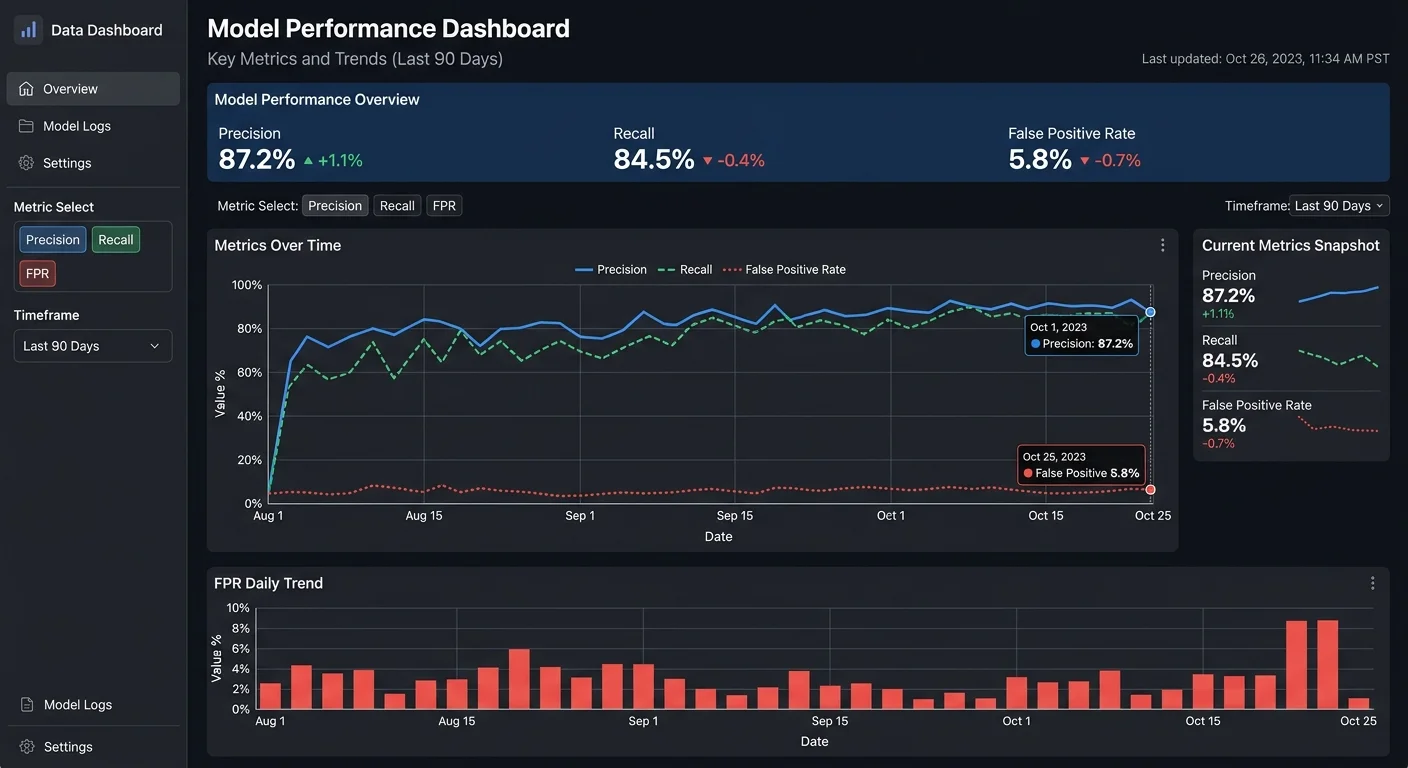
Network environments change constantly. New applications get deployed, employees shift to remote work, mergers bring entirely new subnets online. What counted as "normal" three months ago may look completely different today. Monitor your model's performance metrics weekly: track precision, recall, F1 score, and the volume of alerts generated. A sudden increase in alerts without a corresponding rise in confirmed incidents signals that your baseline has drifted and the model needs retraining.
Statistical drift detection methods like the Page-Hinkley test or Population Stability Index (PSI) can automatically flag when input feature distributions shift beyond acceptable bounds. Set up automated pipelines that trigger retraining when PSI exceeds 0.2 on any critical feature. This proactive approach prevents the gradual degradation that makes many fraud detection AI systems less effective over time. Without drift monitoring, a model that performed brilliantly at launch can become nearly useless within six months.
Seasonal patterns like end-of-quarter traffic spikes or holiday periods can trigger false drift alerts. Account for these cycles in your monitoring baselines.
Establish Feedback Loops
Every alert that a security analyst investigates generates valuable training signal. Build a feedback mechanism where analysts label alerts as true positive, false positive, or needs investigation. Store these labels alongside the original feature vectors in a structured feedback database. This labeled data becomes your most valuable asset for supervised model improvement, far more relevant than public benchmark datasets because it reflects your specific environment and threat landscape.
Schedule quarterly model retraining cycles that incorporate accumulated analyst feedback. During retraining, compare the new model against the production model on both historical test sets and recent analyst-labeled data. Only promote the new model if it improves on both dimensions. Track your improvement over time: most mature organizations see false positive rates decrease by 30 to 50 percent within the first year of systematic feedback integration. This compounding improvement is what transforms an outlier detection experiment into a production-grade security capability.
Frequently Asked Questions
?How do I calculate DNS query entropy scores for anomaly detection?
?Should I use unsupervised or supervised models for network threat detection?
?How long does building a baseline dataset for cybersecurity AI actually take?
?What's the biggest mistake teams make when deploying anomaly detection in production?
Final Thoughts
Building an effective AI anomaly detection system for cybersecurity is an iterative process, not a one-time deployment. Start with solid data engineering, pick models that match your labeled data availability, deploy with real-time infrastructure, and commit to continuous monitoring and retraining.
The organizations that succeed treat their detection models as living systems that evolve alongside their networks and adversaries. With the practical steps outlined here, data analysts and scientists can move from prototype to production with confidence, catching the threats that static rules will always miss.
Disclaimer: Portions of this content may have been generated using AI tools to enhance clarity and brevity. While reviewed by a human, independent verification is encouraged.