AI anomaly detection and fraud detection have become indispensable tools for data professionals working to protect organizations from financial losses and reputational damage. Every year, businesses lose an estimated 5% of revenue to fraud, and traditional rule-based systems catch only a fraction of sophisticated schemes. Modern AI-powered fraud detection systems analyze massive datasets in real time, flagging outlier transactions and behavioral patterns that human reviewers would miss entirely.
For data analysts and scientists, understanding how these systems work is not just intellectually interesting; it is a professional necessity. The techniques behind AI fraud detection draw on statistical modeling, machine learning, and deep learning to surface anomalies buried in noisy data.
This guide walks you through the core methods, practical implementation steps, and real-world use cases so you can build or improve fraud detection pipelines in your own work.
Key Takeaways
- AI fraud detection combines supervised and unsupervised learning to catch known and unknown fraud patterns.
- Feature engineering is often more important than model selection for detecting outlier transactions.
- Real-time scoring requires low-latency infrastructure that balances speed with detection accuracy.
- Ensemble methods consistently outperform single-model approaches in anomaly detection benchmarks.
- Continuous retraining is mandatory because fraud tactics evolve faster than static models can adapt.
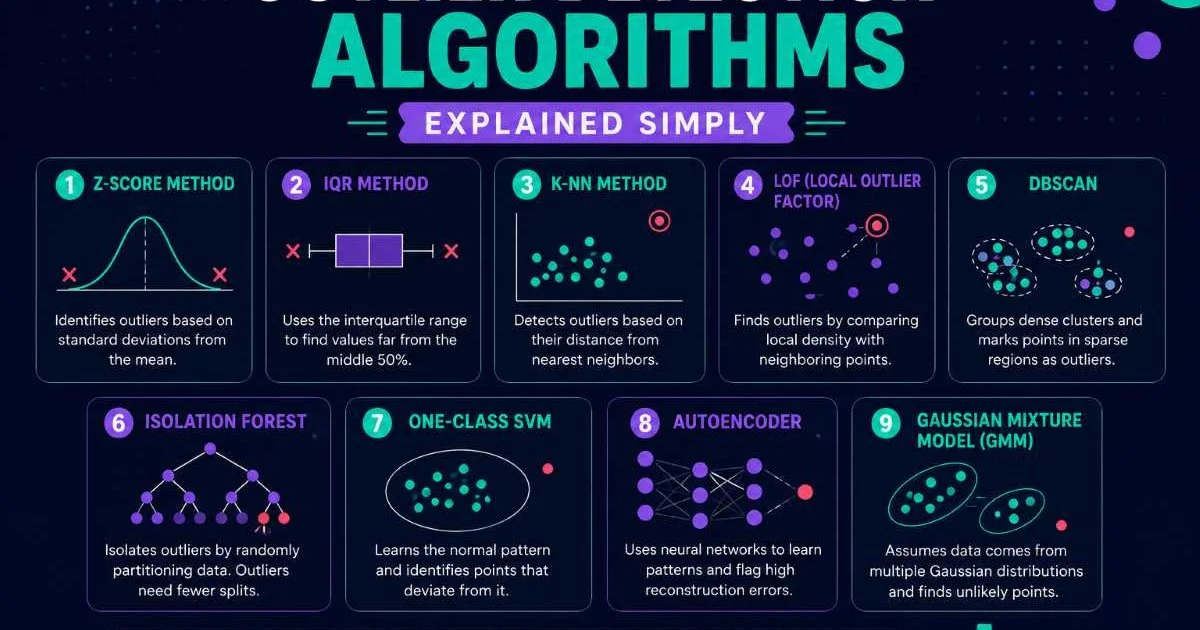
1. Understand the Core AI Methods Behind Fraud Detection
Supervised Approaches
Supervised learning models require labeled datasets where each transaction is tagged as fraudulent or legitimate. Gradient-boosted trees (XGBoost, LightGBM) dominate production fraud systems because they handle tabular data well, train quickly, and provide interpretable feature importance scores. Random forests remain a solid baseline, especially when your labeled dataset is small. The challenge is class imbalance: fraud typically represents less than 1% of all transactions, so you need techniques like SMOTE, cost-sensitive learning, or stratified sampling to avoid a model that simply predicts "not fraud" every time.
Neural networks, particularly feed-forward architectures with dropout regularization, can capture nonlinear relationships in large feature spaces. However, they require significantly more data and compute than tree-based models, and their black-box nature makes compliance teams nervous. For most data science teams starting a fraud detection project, gradient-boosted trees offer the best trade-off between accuracy, speed, and interpretability. If you want a deeper grounding in how AI anomaly detection works across different domains, that foundation will help contextualize the supervised approach within a broader toolkit.
Unsupervised and Hybrid Techniques
Unsupervised methods shine when you lack labeled fraud examples, which is common in new product lines or emerging markets. Isolation Forest, Local Outlier Factor, and autoencoders all work by learning what "normal" looks like and flagging deviations. Isolation Forest is particularly effective for outlier detection in high-dimensional data because it isolates anomalies rather than profiling normal points, making it computationally efficient. Autoencoders learn compressed representations of legitimate transactions; when reconstruction error spikes, the input is likely anomalous.
Hybrid approaches combine supervised and unsupervised models in a single pipeline. One common pattern is using an unsupervised model to generate an "anomaly score" feature, then feeding it into a supervised classifier alongside other features. This gives your gradient-boosted model a powerful signal about statistical unusualness without requiring separate manual rules. In practice, hybrid systems catch 15% to 30% more fraud than either approach alone, according to multiple industry benchmarks.
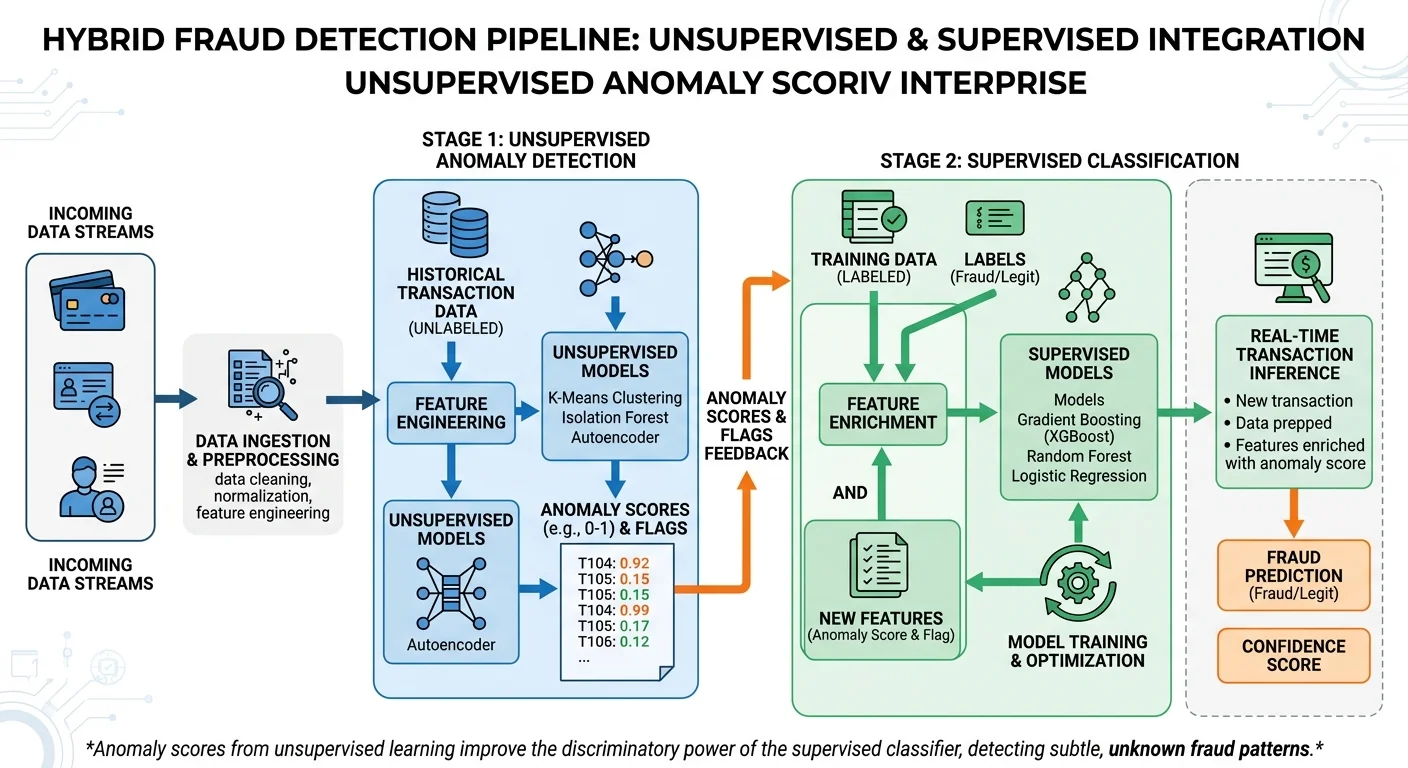
2. Build Your Feature Engineering Pipeline
Transaction-Level Features
Raw transaction data rarely contains enough signal for accurate fraud detection. You need to engineer features that capture context. Start with the basics: transaction amount, time of day, day of week, merchant-generated code, and geographic distance between the cardholder's home and the transaction location. Ratio features are particularly powerful. For example, dividing the current transaction amount by the customer's average transaction amount over the past 30 days produces a simple but effective anomaly indicator.
Velocity features count how many transactions occurred in a short window. A card that processes five transactions in ten minutes at different merchants is far more suspicious than one transaction per day. Similarly, distinct merchant counts, distinct country counts, and channel-switching frequency (online to in-store to mobile) all add predictive power. These features are straightforward to compute but require a well-designed streaming data infrastructure to generate at scoring time.
Create a feature store that computes aggregated features in near real time, so your training and serving pipelines use identical feature definitions.
Behavioral Aggregations
Beyond single transactions, behavioral profiling captures patterns over days, weeks, and months. Calculate rolling averages, standard deviations, and percentile ranks for each customer's spending. A transaction at the 99th percentile of a customer's personal spending distribution is a stronger fraud signal than a transaction that is simply large in absolute terms. These personalized baselines dramatically reduce false positives because they adapt to individual behavior rather than applying blanket thresholds.
Graph-based features add another dimension. When you model relationships between accounts, devices, IP addresses, and merchants as a network, fraud rings become visible. Shared device fingerprints, rapid transfers between newly connected accounts, and clusters of accounts accessing the same merchant within seconds all signal coordinated fraud. Protecting your scoring APIs from bot abuse is also important; automated attackers can probe your system to learn its thresholds, which is why strong API protection against bots and abuse matters for any production fraud system.
3. Deploy Real-Time Scoring and Alerting
Architecture Considerations
A fraud detection model is only as good as the infrastructure serving it. Production systems must score transactions in under 100 milliseconds to avoid degrading user experience. This means your model needs to be optimized for inference speed: tree-based models exported as ONNX or compiled with Treelite, or neural networks served via TensorFlow Serving or TorchServe. Feature retrieval from your feature store adds latency, so caching frequently accessed customer profiles in Redis or a similar in-memory store is a standard practice.
Stream processing frameworks like Apache Kafka, paired with Flink or Spark Structured Streaming handle the ingestion pipeline. Each incoming transaction triggers a feature lookup, model scoring, and a decision output (approve, decline, or queue for review). The entire pipeline should be idempotent and fault-tolerant. If a scoring node fails, the system should route requests to a healthy replica without dropping transactions. Monitoring model latency and throughput is just as important as monitoring prediction accuracy.
Never deploy a fraud model without a fallback rule-based system. If your ML pipeline goes down, basic rules should still block the most obvious fraud patterns.
Threshold Tuning and Alert Prioritization
Your model outputs a probability score, but the business needs a binary decision. Setting the right threshold involves a direct trade-off between precision (how many flagged transactions are actually fraud) and recall (what percentage of total fraud you catch). A threshold of 0.5 might yield 85% precision but only 60% recall, while 0.3 might push recall to 80% at the cost of more false positives. The right balance depends on the cost of fraud versus the cost of customer friction.
"The best fraud detection system is one that catches the most fraud while annoying the fewest legitimate customers."
Prioritization layers help investigation teams work efficiently. Rank alerts by model confidence, transaction dollar amount, and customer risk tier. High-value, high-confidence alerts should reach a senior analyst immediately, while lower-priority flags can enter a batch review queue. Some teams add a secondary model specifically trained to predict which alerts are most likely to result in confirmed fraud, effectively building a triage system on top of the detection system. This two-stage approach reduces analyst workload by 40% in some deployments.
| Risk Score Range | Transaction Value | Priority Level | Action |
|---|---|---|---|
| 0.90 to 1.00 | Over $5,000 | Critical | Auto-block, immediate review |
| 0.90 to 1.00 | Under $5,000 | High | Auto-block, queue for review |
| 0.70 to 0.89 | Over $5,000 | High | Hold transaction, alert analyst |
| 0.70 to 0.89 | Under $5,000 | Medium | Allow, flag for batch review |
| 0.50 to 0.69 | Any | Low | Allow, log for monitoring |
| Below 0.50 | Any | None | Allow, no action |
4. Apply AI Fraud Detection Across Industry Use Cases
Financial Services
Credit card fraud detection is the most mature application of AI-based data anomaly analysis. Major card networks process over 500 million transactions daily, and their models must balance sub-50ms latency with detection rates above 90%. These systems combine transaction-level scoring with network-wide pattern analysis, catching card-testing attacks (small purchases to verify stolen card numbers) alongside large-scale account takeovers. Banks also apply similar AI fraud detection techniques to wire transfers, ACH payments, and loan applications.
Insurance claims fraud represents another high-value use case. Models analyze claim narratives using NLP, cross-reference claimant history, and flag statistical outliers in claim amounts or timing patterns. A claimant who files three water damage claims in two years across different properties is an obvious red flag, but AI models can spot subtler patterns like coordinated claims from the same repair contractor or medical provider. The National Insurance Crime Bureau estimates that fraud adds $308 billion in annual costs across the U.S. insurance industry.
E-Commerce and Digital Platforms
E-commerce platforms face account takeover fraud, promotion abuse, and payment fraud simultaneously. AI anomaly detection models score user sessions holistically, analyzing login behavior, browsing patterns, cart composition, and payment method usage. A sudden shift from a user's typical browsing device, combined with a shipping address change and a high-value purchase, triggers a review. Platforms like Stripe and PayPal publish research showing that ensemble models (combining transaction scoring with device fingerprinting and behavioral biometrics) reduce fraud losses by 25% compared to single-signal systems.
Healthcare fraud detection uses similar outlier detection principles applied to claims data. Models flag providers billing for unusual procedure combinations, patients receiving prescriptions from an abnormally high number of doctors, and geographic anomalies in service delivery. Government agencies also deploy AI fraud detection for tax return fraud, benefits fraud, and procurement fraud. The common thread across all these use cases is the same: define normal, measure deviation, score risk, and act on the highest-confidence anomalies.
Industry-specific regulations (PCI DSS for payments, HIPAA for healthcare) impose constraints on what data you can use and how models must be documented.
Frequently Asked Questions
?How do I handle class imbalance when training a fraud detection model?
?When should I use Isolation Forest instead of XGBoost for fraud detection?
?How often do I need to retrain an AI fraud detection model?
?Is feature engineering really more important than picking the right model?
Final Thoughts
Building an effective AI fraud detection system requires more than picking a model and deploying it. Feature engineering, real-time infrastructure, threshold tuning, and continuous retraining all play equally important roles.
The best systems combine supervised and unsupervised anomaly detection in hybrid architectures that adapt to evolving fraud tactics. Start with strong baselines, invest in your feature pipeline, and measure everything. Fraud detection is an adversarial problem, and the teams that iterate fastest will always have the upper hand.
Disclaimer: Portions of this content may have been generated using AI tools to enhance clarity and brevity. While reviewed by a human, independent verification is encouraged.