AI anomaly detection in real time has become a non-negotiable capability for organizations handling high-velocity data streams. Whether you're monitoring network traffic, scanning financial transactions for fraud, or watching IoT sensor readings, the ability to flag outliers as they happen (not hours later) separates proactive response from costly damage control. Traditional batch processing simply cannot keep pace with modern data volumes.
Real-time anomaly detection combines streaming architectures, machine learning models, and automated alerting to catch problems the moment they emerge. If you want to understand the foundations behind these systems, our guide on what AI anomaly detection is and how it works provides essential background. This article walks you through the practical steps of building and deploying a real-time detection pipeline, from choosing the right tools to tuning your models for production workloads.
Key Takeaways
- Real-time anomaly detection requires streaming infrastructure, not traditional batch pipelines.
- Choose algorithms based on your data dimensionality, latency budget, and labeling availability.
- Feature engineering for streaming data demands windowed aggregations and incremental statistics.
- Alert fatigue from false positives kills adoption faster than missed anomalies.
- Start with a focused use case, then expand detection coverage incrementally.
Step 1: Choose Your Streaming Architecture and Data Pipeline
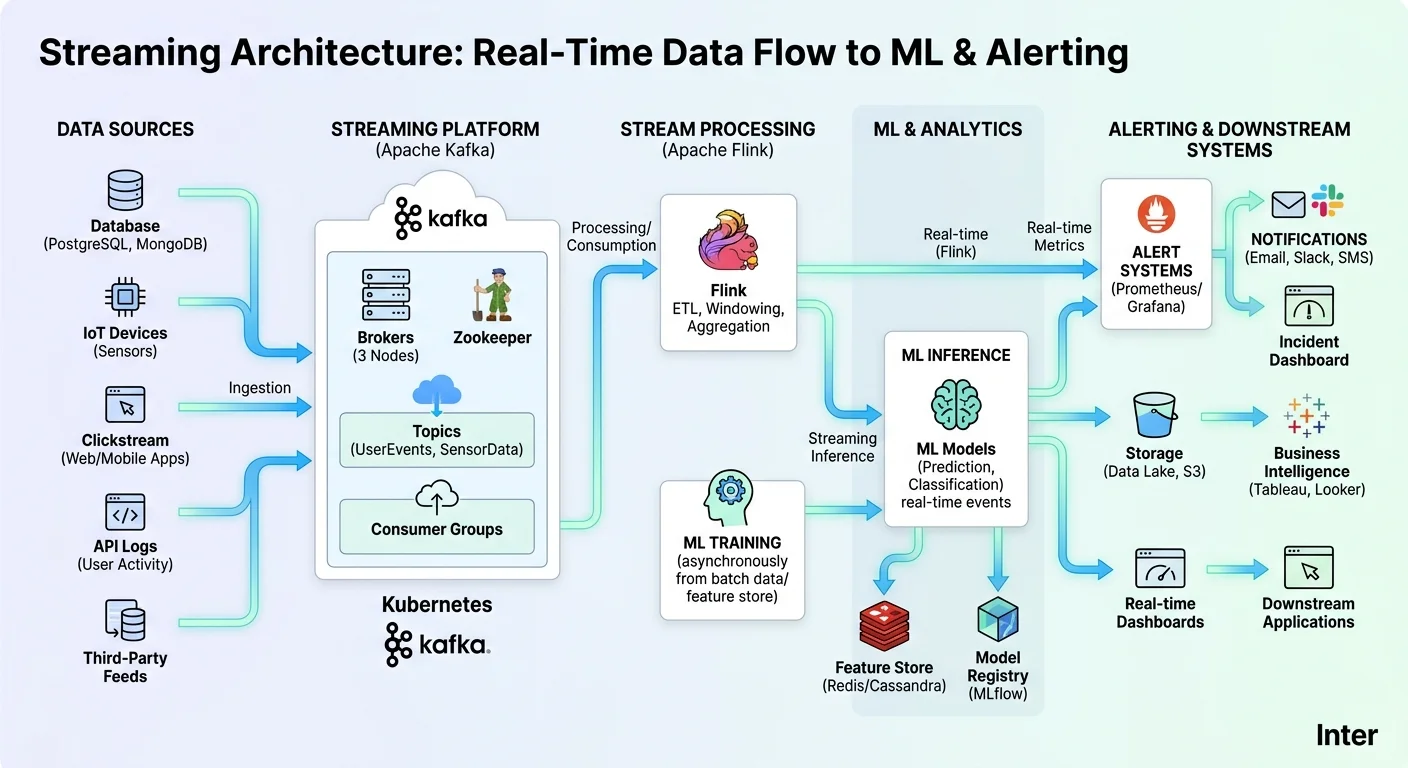
Your detection system is only as good as the infrastructure feeding it. Real-time anomaly detection demands a streaming platform that can ingest, buffer, and deliver data with sub-second latency. Apache Kafka remains the dominant choice for most production environments, handling millions of events per second with durable, replayable message logs. Apache Pulsar offers similar capabilities with built-in multi-tenancy and tiered storage, making it attractive for organizations managing multiple data streams from different teams.
The pipeline itself needs three layers: ingestion, processing, and serving. For the processing layer, Apache Flink and Apache Spark Structured Streaming are the two heavyweights. Flink excels at true event-by-event processing with exactly-once semantics, while Spark Structured Streaming works well if your team already lives in the Spark ecosystem. Both support windowed computations, which you will need for calculating rolling statistics and aggregated features that feed your detection models.
Key Platform Options
Cloud-managed options reduce operational burden significantly. AWS Kinesis, Google Cloud Dataflow, and Azure Stream Analytics all provide serverless streaming with auto-scaling. These platforms integrate tightly with their respective ML services, simplifying the path from data ingestion to model inference. For teams without dedicated infrastructure engineers, managed services cut weeks off deployment timelines and remove the burden of cluster management.
Before committing to a platform, estimate your throughput requirements honestly. A system processing 500 events per second has very different needs than one handling 500,000. Over-engineering the pipeline wastes budget, while under-engineering creates bottlenecks that make real-time detection impossible. Run load tests with representative data volumes before locking in your architecture choices, and ensure your platform supports backpressure handling to prevent cascading failures during traffic spikes.
Start with a single Kafka topic and one Flink job. Add complexity only after you validate end-to-end latency meets your SLA.
Step 2: Select and Train Your Detection Algorithms
Algorithm selection depends on three factors: whether you have labeled anomaly data, the dimensionality of your feature space, and your latency constraints. Supervised models like gradient-boosted trees or neural networks deliver the highest accuracy when you have labeled examples. This is common in AI fraud detection, where historical fraud cases provide clear training signal. However, most real-time detection scenarios lack comprehensive labels, pushing you toward unsupervised or semi-supervised approaches.
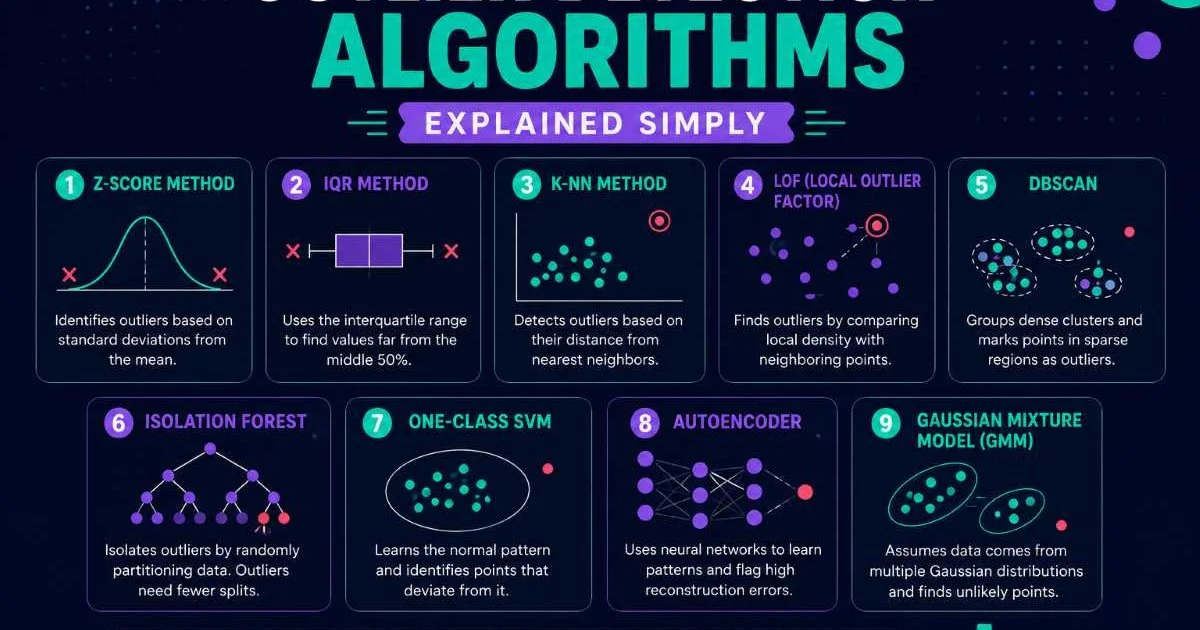
Isolation Forest remains a workhorse for unsupervised outlier detection. It works by randomly partitioning data points and flagging those that require fewer partitions to isolate. The algorithm handles high-dimensional data well and trains quickly, making it a solid starting point. For streaming contexts, you can retrain periodically on recent data windows or use online variants that update incrementally. If you need a deeper understanding of these methods, our breakdown of outlier detection algorithms explained simply covers the fundamentals.
Algorithm Selection Criteria
Autoencoders have gained popularity for data anomaly detection in complex, high-dimensional streams. These neural networks learn to compress and reconstruct normal data. When reconstruction error exceeds a threshold, the input is flagged as anomalous. They work particularly well for image data, network packet payloads, and multivariate time series. The tradeoff is higher computational cost per inference, which matters when you need sub-100ms response times.
Also Check: Google Ads Copy Tips to Lower Your Cost Per Click
Statistical methods like Z-score monitoring and ARIMA-based forecasting still have their place, especially for univariate time series with clear seasonal patterns. They are lightweight, interpretable, and easy to debug. A practical approach is to run statistical detectors as a first-pass filter and then route suspicious events to a more computationally expensive ML model for confirmation. This two-stage pattern reduces compute costs while maintaining detection quality across your entire pipeline.
Step 3: Engineer Real-Time Features and Deploy Models
Feature engineering is where most real-time detection projects succeed or fail. Unlike batch ML, you cannot scan the full dataset to compute features. Instead, you rely on windowed aggregations: rolling averages, counts, standard deviations, and percentiles computed over sliding time windows. For example, a fraud detection system might track the number of transactions per user in the last 5 minutes, the average transaction amount over the past hour, and the geographic distance between consecutive purchases.
"The best anomaly detection model in the world is useless if your features arrive too late to act on."
Feature stores designed for real-time serving, such as Feast, Tecton, or Hopsworks, bridge the gap between offline training and online inference. These platforms let you define features once and serve them consistently in both environments, preventing the training-serving skew that silently degrades model performance. If your features compute differently in production than in training, your model's accuracy guarantees evaporate. Invest the time to validate feature parity before deploying to production.
Deployment Patterns
For model serving, you have two primary patterns. Embedded inference runs the model directly within your stream processing job (e.g., a Flink operator that loads a serialized model). This minimizes latency because there is no network hop for prediction. Alternatively, external model serving via platforms like TensorFlow Serving, Seldon Core, or BentoML provides more flexibility for model updates and A/B testing, at the cost of added network latency. Most teams processing fewer than 10,000 events per second find external serving perfectly acceptable.
Security deserves attention during deployment. Your detection pipeline handles sensitive data, and the API endpoints serving predictions need proper authentication and encryption. For organizations building detection systems that face external traffic, reviewing best API security options for enterprises is a practical step. Model endpoints should not be accessible without proper authorization, especially in cybersecurity applications where AI anomaly detection in cybersecurity systems themselves can become attack targets.
Never deploy a model trained on stale data. Set up automated retraining triggers based on data drift metrics, not arbitrary schedules.
Step 4: Tune Alerts, Reduce Noise, and Iterate
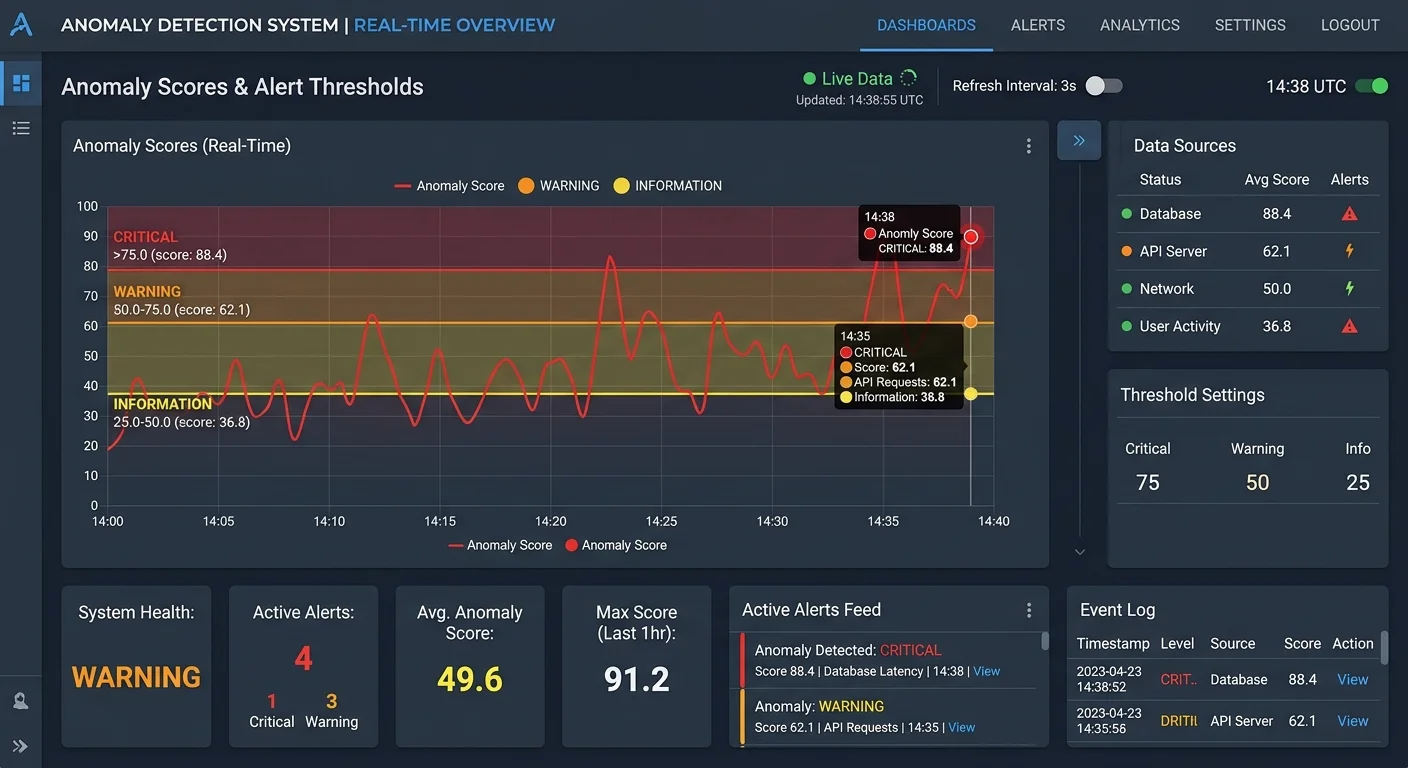
A detection system that fires hundreds of false alerts per day is worse than having no system at all. Alert fatigue causes analysts to ignore notifications, and real anomalies slip through unnoticed. Start by establishing baseline false positive rates during a shadow deployment period where the system flags anomalies without sending alerts. Use this data to calibrate thresholds, adjusting sensitivity until the precision-recall balance fits your operational tolerance.
Anomaly scoring is more useful than binary classification in practice. Instead of labeling every event as "normal" or "anomalous," assign a continuous score representing the degree of abnormality. This lets downstream consumers set their own thresholds based on context. A score of 0.95 might trigger an immediate page to the on-call engineer, while a score of 0.7 lands in a review queue for the next business day. Tiered alerting prevents burnout while preserving coverage for high-severity events.
Building Feedback Loops
The most effective fraud detection AI systems incorporate analyst feedback directly into the model. When an analyst marks a flagged event as a true positive or false positive, that label feeds back into the training dataset. Over time, this creates a virtuous cycle: the model improves, false positives decrease, analysts trust the system more, and they provide more consistent feedback. Without this loop, model performance degrades as data patterns evolve and the training data becomes stale.
Track four metrics religiously: precision, recall, mean time to detection, and mean time to response. Precision tells you what fraction of alerts are real. Recall tells you what fraction of real anomalies you catch. Mean time to detection measures how quickly the system flags an issue after it begins. Mean time to response measures how quickly your team acts on the alert. Optimize all four together, because improving one at the expense of others creates blind spots that accumulate risk over time.
Schedule monthly model reviews where you analyze the top 20 false positives and top 5 missed anomalies to guide retraining priorities.
Frequently Asked Questions
?How do I reduce false positives causing alert fatigue in production?
?When should I choose Apache Flink over Spark Structured Streaming?
?How long does deploying a real-time anomaly detection pipeline typically take?
?Can windowed aggregations keep up with sub-second streaming data volumes?
Final Thoughts
Building a real-time anomaly detection system is an engineering challenge as much as a data science one. The streaming infrastructure, feature pipelines, model serving, and alerting layers all need to work together under tight latency constraints.
Start with a focused use case where the business impact is clear, prove value quickly, then expand. Resist the temptation to build a universal detection platform from day one. Iterative improvement, driven by analyst feedback and production metrics, will always outperform a perfect architecture that never ships.
Disclaimer: Portions of this content may have been generated using AI tools to enhance clarity and brevity. While reviewed by a human, independent verification is encouraged.